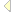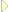The natural starting point is the procedure documentation-contents! which is called by end-documentation .
In the transition to Scheme Elucidator 2 we went from a functional handling of the documentation to an imperative handling. With functional handling, we aggregated (on textual basis) the entire documentation, and we wrote it to the documentation HTML file in end-documentation.
The rationale behind the imperative handling is the following. With the use of the AST-based XHTML mirror, many small HTML fragments are represented as ASTs. These can be, of course, be converted to text, but this either causes lots of garbage collection, or allocation of large chunks of strings. (In LAML, the latter solution is used). Neither solution is attractive. It is better to render these small HTML ASTs directly to an open output port. Rooted in the procedure documentation-contents! via the procedures present-documentation-section!, present-documentation-entry!, do-program-link-documentation!, and do-program-link-documentation-1! this is what we have done.
The function documentation-contents! produce to title, author info, abstract, and the sections of the real documentation. The documentation sections (including the so-called entires) are made in the for loop (  ). The most important is initiated by the function present-documentation-element! within the for loop. It dispatches to present-documentation-section! and present-documentation-entry!. The function present-documentation-section! presents the introductory section text in a color-frame together with a numbered title. Similary, the function present-documentation-entry! presents a documentation entry. Both of these functions call do-program-link-documentation! in which the real interesting work is done, namely conversion of the linking brackets to HTML anchor tags. This function is described in section 6.2 .
). The most important is initiated by the function present-documentation-element! within the for loop. It dispatches to present-documentation-section! and present-documentation-entry!. The function present-documentation-section! presents the introductory section text in a color-frame together with a numbered title. Similary, the function present-documentation-entry! presents a documentation entry. Both of these functions call do-program-link-documentation! in which the real interesting work is done, namely conversion of the linking brackets to HTML anchor tags. This function is described in section 6.2 .
From a overall point of view, do-program-link-documentation! is geared towards a textual representation of the documentation. In the orginal Scheme elucidator (elucidator 1), the holds both for textally authored documentation and for documentation authored in Scheme. (The reason is that, in the orginal elucidator, we used mirror functions that produced text). Therefore, it makes sense for do-program-link-documentation! to traverse its first parameter as text, and do certain transformation on this text.
In Elucidator 2, we will still support the textual documentation format, but we will also support authoring with Scheme and LAML. Using the latter approach, the first parameter of do-program-link-documentation! is now a LAML AST. As an important decision, we do not want to use the textual linking syntax, such as {*...} and {+....} within LAML authored documentation. Rather, in Elucidator 2, we will use Scheme-level referencing forms, and we will have a special form for source marker references. This is a new development, compared for instance with the LAML tutorial, in which we have used LAML/Scheme authoring with textual references. The hybrid format of the original LAML tutorial is therefore not supported any more.
The appropriate location to make the cross road is in the activation of do-program-link-documentation! in present-documentation-entry! and present-documentation-section!. If the intro/body parameters of do-program-link-documentation! (the first parameter) is text, we proceed more or less as in the original elucidator (but imperatively), entering the state machine implemented by program-linking-transition. If the intro/body is an AST, we need to write a new contribution, which bypasses the state machine.
In both a documentation section and a documentation entry we show links to parent and sibling sections/entries. In section 6.6 we describe how this is done.