

1 The sublist problem
In this first section we formulate the general problem we are dealing with, and we motivate it
in terms of a possible application of the solution. 1.1 The problem
| Abstract. This documentation describes a few selected functions from the general.scm library, which we use throughout the LAML software packages. The functions deal with the problem of making a list of sublists from a list. The purpose of the documentation is primarily to demonstrate the Scheme elucidator on a simple example. |
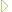
(a b c d e f g h i j)which we want to split into a number of sublists, such as
((a b) (c d) (e f) (g h) (i j))Our concrete motiation for this 'sublisting of a list' is to provide for multi-column presentation of indexes in HTML via tables. In LAML terms we can write
(table
(sublist-by-rows
3
(map as-string '(a b c d e f g h i))
)
1)
This is translated to an HTML table, which you can se here. We can also use a sublisting by column:
(table
(sublist-by-columns
3
(map as-string '(a b c d e f g h i))
"-")
1)
the result of which can be seen here. The functions sublist-by-rows and sublist-by-column are both discussed in subsequent sections.

The real work is done by the function sublist-by-rows-1, which is tail recursive and thus in reality 'iterative'. The first two parameters are passed directly from sublist-by-rows. m is the current length of the latest sublist, res is the parameter in which we accumulate a sublist, and result is the variable in which we accumulate the list of sublists.
The third and fourth case in the conditional are the normal cases.
In the case ( ) that m (the length of the current sublist) is less than n (the desired sublist length) we just put the next element (car lst) into the sublist, res.
In the case (
) that m (the length of the current sublist) is less than n (the desired sublist length) we just put the next element (car lst) into the sublist, res.
In the case ( ) that m and n are equal it is time to finish the sublist, which is done by adding the latest sublist to the result parameter.
We also empty the res parameter, thus preparing to start a new sublist.
) that m and n are equal it is time to finish the sublist, which is done by adding the latest sublist to the result parameter.
We also empty the res parameter, thus preparing to start a new sublist.
The first two cases in the conditional are the base cases. If both lst and res are empty ( ), we just return result.
If lst is empty, but there are pending elements in res (
), we just return result.
If lst is empty, but there are pending elements in res ( ) (the latest sublist), we need to include the pending sublist.
Notice that the last sublist may be of length less than n.
) (the latest sublist), we need to include the pending sublist.
Notice that the last sublist may be of length less than n.
The last thing to care about is all the reversing found in this function. This is the usual 'trick' in tail recursive list functions, where we cons elements on a list. In reality the elements should have been appended to the rear end of the list. To compensate, we reverse the lists before returning them. This is the case both at outer level, and at sublist level.
In order to provide for generality, we need to decide which information the predicate works on. We decide to pass the current element, the previous element (if such a one exits), and the length of list processed until now.
Again, the real work is done by a helping function, which is tail-recursive. But we handle two special cases, namely
empty lists ( ) and singleton lists ( ) at top level. Handling list of length one here provides for a more regular solution
in the helping function, because we then know that the 'previous element' makes sense.
And now to the helping function sublist-by-predicate-1. Besides the list and the predicate it passes the previous element, previous-el, the current list length n, res, and result as parameters. The two latter parameters play the same role as above.
The two base cases ( and  ) are the same as in sublist-by-rows. The more interesting cases are relatively straigthforward.
If the predicate holds on (car lst), previous-el and n (
) are the same as in sublist-by-rows. The more interesting cases are relatively straigthforward.
If the predicate holds on (car lst), previous-el and n ( ) we add the sublist to RESULT, and we start a new sublist in res
immediately. Thus, in some sense we take two steps here: Adding to RESULT, and starting the new sublist. Notice the
way we pass previous-el to the next iteration.
If the predicate does not hold (
) we add the sublist to RESULT, and we start a new sublist in res
immediately. Thus, in some sense we take two steps here: Adding to RESULT, and starting the new sublist. Notice the
way we pass previous-el to the next iteration.
If the predicate does not hold ( ) we extend the current sublist with (car lst). Just straight ahead...
) we extend the current sublist with (car lst). Just straight ahead...
It is interesting to notice that the general solution is less complicated than the specific solution, which we made in section 2.1. This is a pattern we often encounter.
(a b c d e f g h i j)We now want to split the list into this list
((a f) (b g) (c h) (d i) (e j))If sublists of this list are considered as rows in a table we have in reality achieved a sublisting of the list in two columns, where the first colum contains (a b c d e) and the second column contains (f g h i j). In that respect, the list has been sublisted by column, and not by row.
The function is called sublist-by-2columns. The algorithmic idea is to use sublist-by-rows, which we have seen above, to split the list in a front-end and a rear-end. The two list can then easily be paired together to the desired result.
If we take a close look at sublist-by-2columns we need to make sure that the length of the list is even. If the length is odd, we miss an element. This gives us a problem: What should the missing element be in case the list is of odd length? There is no good general answer, so we pass the extra, compensating element as a parameter to sublist-by-2columns.
Now the implementation is easy to understand. We bind the name row-sublst to a list of sublists ( ). The lengths of
the sublists are half of the length of the original list. This accounts for the quotient form.
We use a simple mapping (
). The lengths of
the sublists are half of the length of the original list. This accounts for the quotient form.
We use a simple mapping ( ) on the first and second elements of row-sublst in order to pair the
elements, and in this way we get the rows of 'the column solution'.
) on the first and second elements of row-sublst in order to pair the
elements, and in this way we get the rows of 'the column solution'.
The function is sublist-by-columns. The parameters are n (the number of columns), the list lst, and the extra filling element (as discussed above).
The solution is the same as in sublist-by-2columns: We split the list in roughly L div n sublists, produced by sublist-by-rows. Then we make a pairing of the first elements, the second elements, etc.
The first thing that we have to ensure is that the length of the list is a multiplum of n.
This is done by adding extra elements, if necessary, to the rear end of the list ( ). In case
the length of L isn't a multiplum of n we get the following calculation: If
(length lst) = L, we need to add E =(((L div n) + 1) * n) - L extra elements.
The reason is that L + E = n * (+ 1 (L div n)).
We are now left with af list of sublists, which need to be 'paired' by first elements, second elements, etc. Let us be concrete in terms of an example where lst is to be divided into n columns.
lst = (a b c d e f g h i j)
n = 3
Sublists = ((a b c d)
(e f g h)
(i j - -))
Result = ((a e i)
(b f j)
(c g -)
(d h -))
We see that the elements of lst appear correctly in the columns of Result. The elements '-' are
the extra elements.We have to make a function which takes a list of list as input, and which produces the necessary first element list, second element list, etc.
This function is multi-pair. Given a list of lists it returns a list of lists. The function collects all first elements, etc. The program is easy to make by recursion. In the interesting case we map car over all the lists, giving us the list of first elements. We form a list of these 'cars' and a recursive solution on the cdrs.
For completeness we need to make multiplum-of, which is trivial.