OverviewIn this project, we propose an open-source library, which is an implementation of state-of-the-art time-aware IR approaches in MapReduce. This will serve as a toolkit for effective and efficient search on temporal Web collections. In such collections, documents are created and/or edited over time, and examples are web archives, news archives, blogs, personal emails and enterprise documents. The expected outcome of this project can be seen as a pragmatic contribution aimed at supporting similar endeavors, i.e., prospective researchers or practitioners, to study temporal search or advance it into temporal exploration and analytics studies. |
Follow us on Twitter Software Library: 
|
Data Collections
We aim at working with two types of temporal document collections:
- Non versioned: TREC Web collections (e.g., ClueWeb2009 and TREC Blog) and news archives (e.g., New York Times Annotated Corpus).
- Versioned: UK and DE domain web archive collections
MapReduce BasicMapReduce is a programming framework [9] for processing huge amounts of unstructured data in a massively parallel way.
|
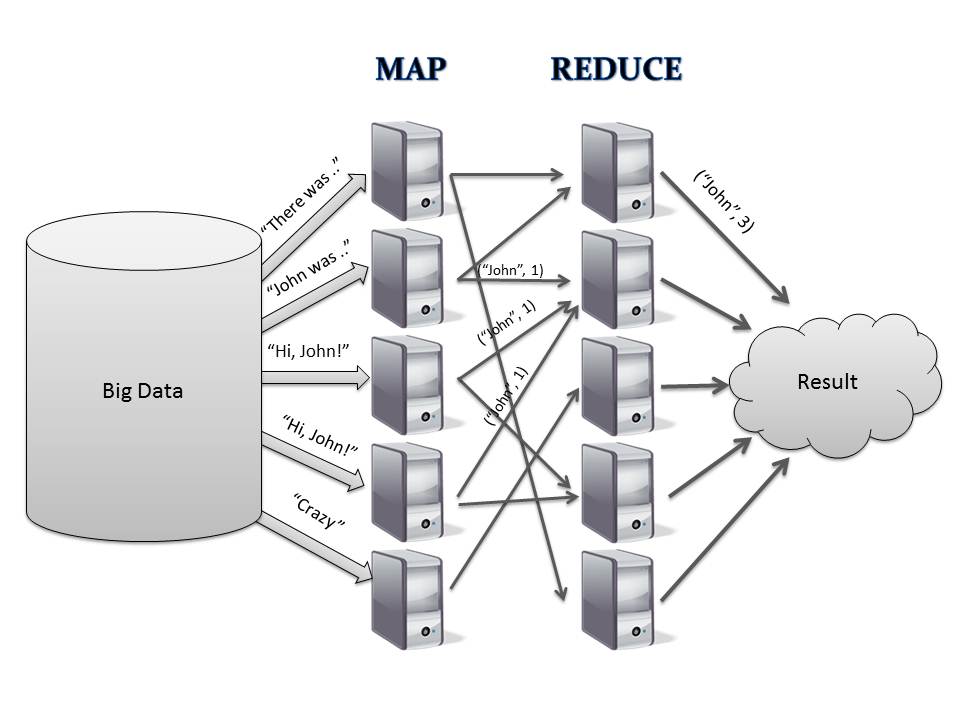
|
Hadoop-based ToolsThere are existing Hadoop-based frameworks that provide solutions for large-scale data analysis. We present here four frameworks, namely, HBase (for storage), SolrCloud+Hadoop (for indexing), Mahout (for machine learning) and R + Hadoop (for statistical analysis). |
|